Learning Aims and Objectives:
Aim: In this week's page, students will learn the
Objectives:
1. By the end of this week's page students will be able to.
2. By the end of the week's page students will be able to.
P3.1 Fault analysis tools and their applications to identify problems
Why do companies need to use tools to monitor and analyse faults? Is it not better to have a system that alerts when there are just faults and then they can be fixed? The answer to these questions is quite simple, not all faults that are the same are triggered in the same way. We must remember that at any one time, a network, computer or digital device could be processing any number of actions in the background that users might not be aware of. The use of tools to monitor and analyse faults provides engineers and technicians an opportunity to reflect on the logs of the systems to understand potential triggers.
Have you ever had a situation where you have had a fault and someone else has also experienced it? Were they triggered at the same time? Were you both working on the same thing with the same applications or elements open? How did you resolve this issue? what was it? Was it the same process as the other person?
Having looked at and used some of the network/tone testers in a lab setting, research and review the different testers available and the features and functions that they have and can do. Discuss where these might be used and the benefits to the users.
How are faults identified on the systems that we use? Let's look into the most common.
Traditional Techniques used to fault find used flow charts to ask users questions to discount or discredit areas that the issue wasn't. These flow charts were significant in thier breath of the topic area, and became almost obsolete due to the large amount of variables and possible resolutions. However a flow chart can be seen in action to help Sheldon find a friend.
System alerts
A flag when a system condition is outside predetermined parameters
Common system alerts come in the form of beep codes, these codes act like a morse code for technicians. The codes themselves are short and long pulses of sound generated by a small speaker mounted to the main circuit board.
On newer devices small lcd screens display codes that can be cross referenced against the manufacturers information doucmentations provided with the device or online.
Flow Chart Operators
Lets consider the use of flowcharts to support the resolution of a sound card. Using the flow chart notation above create a chart that some one could use to fix a sound card issue.
Activity/error logs
Record of all interactions and events within network systems
The importance of logging only to clear to reflect on possible clues to the lead up to faults and thier diagnosis. Within the educational sector a shared academic network called "Janet" is used. This network is operated and supported by the Jisc group and is governed by UKERNA (United Kingdom Education and Research Networking Association), which is a nonprofit group of the U.K. Higher Education Funding Council.
Within Jisc website they have a series of support documentation that further discusses the use and need for the use of Activity/error logs
Jisc Activity and Error loggingResearch using the link above what areas are suggested for those that use and work with the Janet network to log.
What do these logs look like and what files are they?
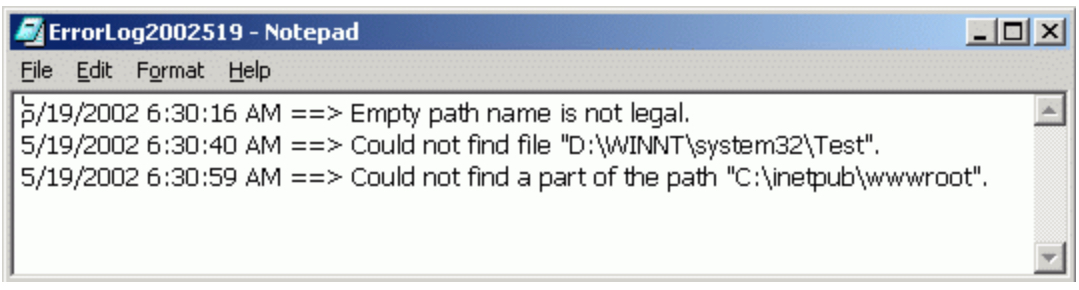
Log files are not formatted documents that present information in pretty headings and images in most examples. These files tend to have rows of information that is separated over lines for different logged data. As you are able to see in the image below the log is identifying the date time that the log recorded something and a message of the error that was logged and what the user might have been trying to access.
In most situations the log files for networks and programs are basic text files, that if attempted to be opened, would in a windows environment by opened in notepad. The files are automatically generated by the systems at specific times and if needed manually.
Live traces
identify any network traffic or activity in real-time
Network traffic can be monitored when its working in real time but what about when it isn't!?
Case Study:
Installation of the network and electrical infrastructure for the T-Level room:
Prior to the creation of a bespoke room for the delivery of the NCFE Digital Support Services T-Level program a college bought in a contractor to set up network and PowerPoints in a range of places in the room to enable the placement of IT equipment in new locations from the original that previously existed in the room. These network faceplates had 2 connections that ran back to a patch panel located in the server room. These patch panels where then connected via patch cables to 10 gigabit switches that ran 10 gigabit SFP+ fiber cables to a fibre switch that connected to the main servers within the organisation. The problems occurred around a week after the PC's were set up in the classroom, some of the networked and previously functional PC's showed no network activity. The initial thoughts around this issue was that the network port had been damaged in some way, so a simple fault remedy was suggested of changing to another port in the network faceplate. However, this didn't resolve the issue, so it was suggested to try the next available port, suprisingly the issue remained. The next step was to swap out the cable for another that was known to work, and test this on all ports used previously. The result was still the same! Next was to try another PC in case the network interface card in the PC was faulty. Again this issue remianed.
Increasing frustrated with the result we used a network/tone tester to check the cable. The tester sends pulses of electrical current down the cable with a transmitter that at the other end the receiver lights up the cable strands that are connected. The result of this test identified that only 2 stands of the 8 were actually transmitting. This would suggest that the faceplate module may have loose connections in the back. On opening up the faceplate it was clear that the cable had been adjusted using electrical cable joiners to extend the cable that was then connected to the faceplate module. The next step was to remove those connectors and to cable directly to the faceplate module the strands of wire and remove the extensions completely. Hopeful that this would be the fix the cable was then checked and tested again. However this was not the case and still the issue remained, and the strands 5 and 6 were the only operational pair. What next!! The fault was still there what more can be done? The next step was to use a more advanced network testing tool that allows testing of the length of the cable in the hope that there is information on whether there is a break somewhere in the cable. This tool worked and identified that the cable had a break approximately 7.4 meters down the cable that should be 60 meters plus. This outcome although not resolved gave a result that suggested that the external contractor had rushed or installed incorrectly the new locations and networks ports and had impacted other ports by doing so.
The outcome of this fault diagnosis resulted in the temporary installation of a network switch in the room connected to 2 known working ports to enable a 2 gig connection that the PC's in the room could connect to whilst the contractor was bought back to reinstall and test the required structure.
Dashboards
A consolidated visual representation of system condition and performance
Files that support this week
English:
Assessment:
Learning Outcomes:
Awarding Organisation Criteria:
Maths:
Stretch and Challenge:
E&D / BV
Homework / Extension:
ILT
→
→
→
→
→
→
Week 2
T&L Activities:
Learning Aims and Objectives:
Aim: In this week's page, students will learn the
Objectives:
1. By the end of this week's page students will be able to.
2. By the end of the week's page students will be able to.
P3.2 The purpose and application of organisational frameworks for troubleshooting and problem management
Problem identification
– identify and isolate faults using diagnostic and analytical tools to establish the probable cause
### **Activity Title: Troubleshooting and Problem Management: Identifying Faults Using Diagnostic and Analytical Tools**
**Objective:**
Students will learn how to apply organizational frameworks for troubleshooting by identifying and isolating faults using diagnostic and analytical tools. This activity focuses on structured problem-solving, using real-world scenarios.
---
## **Activity Sheet:**
### **Part 1: Understanding Troubleshooting and Problem Management (10 minutes)**
1. **What is troubleshooting?**
- Write your own definition of troubleshooting.
2. **What is problem management?**
- Explain what problem management is and why it is important in an organizational context.
3. **Diagnostic Tools:**
- List two diagnostic tools commonly used for troubleshooting in IT or other industries.
You will be given two real-world scenarios. Your task is to identify the potential problem and describe how you would use diagnostic and analytical tools to isolate the fault.
---
#### **Scenario 1: Internet Connection Issue**
You are working in the IT department of a company, and employees are complaining that they are unable to connect to the internet. Some employees can connect but the connection is very slow, while others cannot connect at all. This issue is affecting productivity across the office.
- **Step 1: Problem Identification**
What is the first thing you would do to identify the problem? (e.g., checking hardware, software, network settings, etc.)
- **Step 2: Diagnostic Tools**
Which diagnostic tools would you use to isolate the fault? List at least two tools and explain how you would use them (e.g., ping test, network monitoring software).
- **Step 3: Probable Cause**
Based on the information available and the tools used, what could be the most likely cause of the issue? Provide reasoning for your answer.
---
#### **Scenario 2: Software Crash**
You work in an organization that uses a custom-developed software application for its daily operations. Over the past week, several employees have reported that the software crashes when they try to run a specific report. The crash happens inconsistently but always when this particular function is used.
- **Step 1: Problem Identification**
What initial steps would you take to identify the problem (e.g., user reports, error logs, etc.)?
- **Step 2: Diagnostic Tools**
Which tools would you use to diagnose the issue? (e.g., reviewing logs, running a system check, etc.)
- **Step 3: Probable Cause**
Based on your analysis, what is the most probable cause of the crash? Explain how you arrived at this conclusion.
---
### **Part 3: Reflection and Discussion (10 minutes)**
- Reflect on the scenarios above. Why is it important to have a structured framework for troubleshooting and problem management in an organization?
Logging
Review fault history, identifying potential trends and issues
Action plan
Plan or strategy for repair, restoration and prevention of further issues
Escalation
To an appropriate manager, specialist or external third-party
Solution implementation
Implement required changes to fix and restore services
Problem closure and review
Notify user and document any configuration changes
Files that support this week
English:
Assessment:
Learning Outcomes:
Awarding Organisation Criteria:
Maths:
Stretch and Challenge:
E&D / BV
Homework / Extension:
ILT
→
→
→
→
→
→
Week 3
T&L Activities:
Learning Aims and Objectives:
Aim: In this week's page, students will learn the
Objectives:
1. By the end of this week's page students will be able to use and adapt problem analysis tools and approaches to diagnose or identify areas of fault or issue..
2. By the end of the week's page students will be able to create personal straterges to support them in thier diagnosis and analysis of issues and faults within thier own practices and, future practices.
P3.3 Root cause analysis approaches and their applications within problem management:
The 5 ‘whys’
An iterative questioning technique, the 5 Whys is a simple but effective way to get to the bottom of a problem by asking “why” five times, or more if needed. It’s like peeling back layers of an onion, going deeper each time until you find the true cause of the issue, not just the surface-level problem.
Here’s how it works:
• You start by identifying the problem.
• Then, you ask why the problem happened.
• After you get the first answer, you ask why again to dig deeper.
• You keep repeating this process, usually about five times, until you uncover the root cause of the issue.
In digital support services, this technique helps teams figure out why things go wrong, whether it’s related to technology not working, users having issues, or systems failing. By understanding the true cause, companies can fix problems effectively and prevent them from happening again.
Example Case Studies in Digital Support Services:
1. Slow Website Performance
• Problem: Users report that a website is loading slowly.
• 1st Why: Why is the website slow? Because the server response time is long.
• 2nd Why: Why is the server response time long? Because it’s overloaded with too many requests.
• 3rd Why: Why are there too many requests? Because a lot of bots are making fake requests.
• 4th Why: Why are bots making fake requests? Because there’s no filtering system in place to block them.
• 5th Why: Why is there no filtering system? Because it wasn’t set up during the website’s initial configuration.
• Solution: Set up a bot-blocking system to reduce server load and improve performance.
2. Customer Complaints About Software Crashing
• Problem: A company’s support team receives multiple complaints that their app is crashing.
• 1st Why: Why is the app crashing? Because it’s running out of memory.
• 2nd Why: Why is it running out of memory? Because it’s using too much data.
• 3rd Why: Why is it using too much data? Because the images in the app are not compressed.
• 4th Why: Why aren’t the images compressed? Because the developers didn’t optimize them.
• 5th Why: Why weren’t the developers optimizing images? Because they weren’t aware of the issue until users complained.
• Solution: Train developers on data optimization and perform regular app performance tests.
3. Repeated Failed Logins by Customers
• Problem: Customers are having trouble logging into their accounts.
• 1st Why: Why can’t they log in? Because their passwords are being rejected.
• 2nd Why: Why are passwords being rejected? Because the system doesn’t recognize them.
• 3rd Why: Why doesn’t the system recognize them? Because some users are resetting their passwords repeatedly.
• 4th Why: Why are they resetting their passwords repeatedly? Because they can’t remember them.
• 5th Why: Why can’t they remember their passwords? Because the system has strict password requirements that are hard to remember.
• Solution: Implement a more user-friendly password recovery system or use passwordless login methods like biometrics or magic links.
The 5 Whys technique helps digital support services dig deeper to find solutions that aren’t just quick fixes but address the real problem, saving time and improving user experiences in the long run.
5 Whys Game
Objective:
This activity helps students understand the 5 Whys technique by creating a game where they identify the root cause of a problem. It encourages teamwork, critical thinking, and communication skills. Setup:
• Split the class into pairs (Pair A and Pair B).
• Each pair will create a simple problem scenario and guide the other pair through the 5 Whys questioning process to find the root cause.
• After creating their scenarios, the pairs will swap and solve each other’s problem using the 5 Whys method.
Instructions: Part 1: Creating the Problem Scenario (10-15 minutes)
1. Create a Problem: In each pair, students come up with a fictional problem for the other pair to solve. The problem should be related to everyday experiences like technology, school, or a common inconvenience. The problem can be simple, such as:
• “The Wi-Fi isn’t working.”
• “A game console keeps freezing.”
• “The printer won’t print.”
2. Think of the Root Cause: After creating the problem, the pair should also come up with a potential root cause of the issue (e.g. Wi-Fi router is out of date, or the console needs an update) to make sure they can guide the other pair toward the answer.
3. Develop Hints: Prepare answers for each of the 5 Whys steps that will eventually lead to the root cause. Make sure the hints lead the problem-solvers to dig deeper, but don’t give away the solution immediately. Example:
• Problem: “The laptop won’t turn on.”
• Why #1: Why isn’t the laptop turning on? (The battery is dead.)
• Why #2: Why is the battery dead? (It wasn’t charged overnight.)
• Why #3: Why wasn’t it charged overnight? (The charger wasn’t plugged in properly.)
• Why #4: Why wasn’t it plugged in properly? (The power strip was switched off.)
• Why #5: Why was the power strip switched off? (It was switched off to save power, but the student forgot to turn it back on before charging.)
Part 2: Swapping and Solving (10-15 minutes)
1. Swap Problems: Once both pairs have completed their problem scenarios, they swap with another pair. Now each group has a new problem to solve using the 5 Whys technique.
2. Solve the Problem:
• The pair solving the problem will ask “why” questions, starting with the surface problem.
• The other pair (the creators of the problem) will provide answers based on the hints they prepared.
• The goal is for the solvers to identify the root cause after asking at least 5 “why” questions.
3. Reflection: After solving, each pair should discuss:
• Did they reach the root cause? How difficult was it to ask the right “why” questions?
• Were the answers clear, or did they need more information?
• How did this process help them understand the problem better?
Part 3: Group Discussion (5-10 minutes)
After both pairs have completed the activity, come together as a class to reflect on the experience. Ask students:
• What challenges did they face when asking “why”?
• Did anyone find a different root cause than expected?
• How can this technique be useful in real life, especially in areas like technology or problem-solving?
Extensions:
• Role Reversal: Have the pairs switch roles again and create new problems.
• Real-World Scenarios: Ask pairs to think of real issues they’ve encountered in their daily lives (like a broken phone charger or app not working) and apply the 5 Whys.
This activity is designed to be fun, engaging, and hands-on, helping students apply the 5 Whys technique in a creative way while working together!
Fishbone diagram
A Fishbone Diagram, also known as a Cause and Effect Diagram or Ishikawa Diagram, is a visual tool used to identify and organise potential causes of a problem or effect. The diagram resembles a fish skeleton, where the “head” represents the main problem, and the “bones” branching off represent different categories of causes. The concept was developed by Kaoru Ishikawa, a Japanese quality control expert, in the 1960s.
Key Components
1. Head: The problem or effect you want to analyse (e.g., “Customer Satisfaction Issues”).
2. Spine: The central line leading to the head.
3. Bones: Major categories of causes that contribute to the problem. Common categories include:
• People: Issues related to staff performance or training.
• Processes: Problems in how services are delivered or tasks are completed.
• Technology: Issues with software, hardware, or tools used.
• Materials: Resources and materials that might affect the outcome.
• Environment: External factors that impact the situation.
Application in Digital Support Services
In the context of digital support services, a Fishbone Diagram can help teams identify the root causes of issues that customers face, leading to more effective solutions. Here’s how it can be used:
1. Identifying Technical Problems: For example, if a company receives complaints about its online support portal being difficult to navigate, a Fishbone Diagram can help identify whether the issues stem from:
• Poor user interface design (Technology)
• Lack of training for support staff (People)
• Ineffective processes for addressing user queries (Processes)
2. Improving Customer Service: If customer satisfaction scores are low, the Fishbone Diagram can break down potential causes, such as:
• Slow response times (Processes)
• Insufficient staff training (People)
• System crashes or bugs (Technology)
Case Studies and Examples
1. Case Study: A Software Company
A software company used a Fishbone Diagram to analyse customer complaints about their software’s performance. They identified several root causes:
• People: Inadequate training for users.
• Processes: Complicated installation processes.
• Technology: Software bugs that were not resolved quickly.
By addressing these areas, they improved user experience and reduced complaints.
2. Case Study: An E-Commerce Retailer
An e-commerce retailer faced declining sales due to cart abandonment. They used a Fishbone Diagram to analyse the situation:
• Processes: Complicated checkout process.
• Technology: Mobile website issues.
• Environment: High shipping costs.
This analysis led them to simplify the checkout process and improve their mobile site, resulting in increased sales.
Articles and Resources
Here are some articles and resources for further reading on Fishbone Diagrams and their application in digital support services:
1. MindTools - Cause and Effect Analysis: Link
2. Creative Safety Supply - Fishbone Diagram: Link
3. ASQ - Cause and Effect Diagram: Link
4. Quality Management Solutions - The Fishbone Diagram: Link
Utilising a Fishbone Diagram can assist teams in digital support services in understanding and tackling the root causes of problems, ultimately leading to improved customer satisfaction and service delivery.
Fault Finding Using Fishbone Diagrams Objective
In this activity, you will practice using Fishbone Diagrams to identify and analyse the potential causes of a specific fault or problem within a fictional scenario. This task will help you develop your critical thinking and problem-solving skills.
Time Required
30 minutes
Scenario: Café Delights
Background:
Café Delights is a popular coffee shop that has recently been experiencing a decline in customer satisfaction. Customers have complained about various issues, including slow service, incorrect orders, and cleanliness. The management wants to identify the root causes of these problems in order to improve the customer experience.
Task Instructions
1. Set Up Your Diagram:
• On a piece of paper or using a digital drawing tool, draw a large horizontal arrow pointing to the right. At the head of the arrow, write the main problem: “Decline in Customer Satisfaction”.
• Draw several diagonal lines (bones) branching off from the spine of the arrow. These lines will represent different categories of potential causes.
2. Identify Categories:
Use the following categories to organise your causes:
• People: Issues related to staff performance or training.
• Processes: Problems with how orders are taken or prepared.
• Technology: Any issues with the equipment used (e.g., coffee machines, order systems).
• Environment: Factors related to the café’s atmosphere (e.g., cleanliness, seating).
• Materials: Quality or availability of ingredients (e.g., coffee, pastries).
3. Brainstorm Causes:
In each category, brainstorm potential causes that could contribute to the decline in customer satisfaction. Here are some examples to get you started:
• People:
• Are the staff adequately trained?
• Is there high staff turnover affecting service quality?
• Are staff members friendly and attentive?
• Processes:
• Is the ordering process efficient?
• Are there delays in food preparation?
• Is there a lack of communication between front-of-house and kitchen staff?
• Technology:
• Are the coffee machines functioning properly?
• Is the point-of-sale system causing delays?
• Is there a reliable Wi-Fi connection for customers?
• Environment:
• Is the café clean and well-maintained?
• Are there enough seats for customers during peak hours?
• Is the café atmosphere inviting?
• Materials:
• Are ingredients fresh and of good quality?
• Are there shortages of popular menu items?
• Is there proper inventory management?
4. Complete Your Diagram:
After brainstorming, fill in your Fishbone Diagram with the causes you identified. Write each cause on the corresponding bone, ensuring it is easy to read.
5. Discussion and Reflection:
Once you have completed your Fishbone Diagram, discuss your findings with a partner or in a small group. Consider the following questions:
• Which category has the most causes?
• Are there any causes that stand out as particularly impactful?
• What immediate actions could Café Delights take to address these issues?
Conclusion
This exercise will help you understand how to use Fishbone Diagrams for fault finding and problem analysis. By breaking down the issue of declining customer satisfaction at Café Delights, you can identify potential solutions to improve the customer experience.
Failure mode and effects analysis (FMEA)
Identifies which parts of the process or system are faulty
In the digital support services industry, Failure Mode and Effects Analysis (FMEA) can be highly valuable in ensuring reliability, minimising downtime, and improving the overall customer experience. The industry relies on complex digital systems, software platforms, and networks, where failures can have significant operational and business impacts. Here’s how FMEA can be contextualised within this sector:
1. Failure Modes in Digital Support Services
• Software Failures: These could include bugs, crashes, or incompatibilities in the software used to provide support services. A failure might prevent users from accessing critical support tools or resources.
• Network Downtime: Disruptions in network connectivity that hinder communication between support teams and customers, leading to delays in problem resolution.
• Data Breaches or Cybersecurity Issues: Failures in protecting customer data can lead to breaches, data loss, or unauthorised access, which are critical in digital services.
• Poor Integration: Incompatibility between various software systems or tools used in support services, causing disruptions in the workflow or poor user experiences.
2. Effects of Failure
• Customer Dissatisfaction: Failures can lead to delays in resolving customer issues, causing frustration and possibly losing customers.
• Operational Downtime: Extended periods of system unavailability affect the ability of the support team to operate efficiently, impacting overall service delivery.
• Reputation Damage: Cybersecurity issues or consistent service failures can damage the organisation’s reputation, eroding trust with clients.
• Financial Losses: Unplanned outages, lost productivity, and reputational damage can lead to financial consequences, either through lost business opportunities or costs associated with fixing the issues.
3. Severity, Occurrence, and Detection in Digital Support Services
• Severity (S): For digital support services, severity can range from minor inconveniences (e.g., slow service) to critical issues such as complete system shutdowns, impacting service-level agreements (SLAs).
• Occurrence (O): In a digital environment, failure modes with high occurrence might include recurring software bugs, frequent network interruptions, or continual user-reported issues.
• Detection (D): Early detection of failure modes could involve automated monitoring tools, error logs, or customer feedback systems. Failures that are hard to detect, such as latent cybersecurity vulnerabilities, would rank high on the detection scale.
4. Risk Priority Number (RPN)
• In digital support services, the RPN helps identify where proactive improvements are most needed. For example, a failure mode such as a data breach, with high severity (due to legal and reputational risks), moderate occurrence, and low detectability, would have a high RPN. This would signal the need for immediate attention, such as implementing stronger cybersecurity measures or monitoring systems.
5. Mitigation and Prevention in Digital Support
• Automated Monitoring Tools: To minimise occurrences of network and software failures, companies can implement real-time monitoring systems that alert teams when failures are likely to occur.
• Redundant Systems: In the case of network downtime, having redundant systems or backup networks can ensure continued service even if the primary system fails.
• Patch Management and Software Updates: Regularly updating software and applying patches can prevent common bugs and vulnerabilities that lead to system failures.
• Cybersecurity Protocols: Stronger encryption, multi-factor authentication, and real-time threat detection can mitigate the risk of data breaches and security-related failures.
FMEA as a Learning Tool in Digital Support Services:
In this industry, FMEA becomes a proactive learning model for continuously improving digital infrastructure. By routinely analysing failure modes, companies can:
• Enhance their incident response protocols to minimise customer impact.
• Build resilience into their systems by identifying critical failure points before they cause major service disruptions.
• Foster continuous improvement in service delivery by learning from previous failures, which in turn improves customer satisfaction and operational efficiency.
FMEA helps digital support service providers identify and prioritise potential failures, mitigate risks, and enhance overall system reliability, which is crucial for maintaining high levels of service quality and customer trust.
Activity: Failure Mode and Effects Analysis (FMEA) in Digital Support Services Duration: 30 minutes Target Audience: IT Students
Failure Mode and Effects Analysis (FMEA) with an application in Digital Support Services
Activity Overview:
In this activity, students will apply the principles of FMEA to identify potential failure modes in a common Digital Support Services scenario, evaluate the impact, and develop strategies to mitigate these risks. This practical exercise will enhance their problem-solving skills and understanding of risk management in IT service delivery.
Learning Objectives:
• Understand the purpose and process of FMEA.
• Apply FMEA to a real-world Digital Support Services scenario.
• Identify failure modes, their effects, and possible mitigation strategies.
• Present findings in a structured manner.
Scenario: User Account Management System
You work in a Digital Support Services team responsible for managing a company’s User Account Management System. This system handles user account creation, password resets, role assignments, and account deactivation. Ensuring this service operates smoothly is critical to business continuity and user satisfaction.
Task Breakdown (30 minutes): 1. Introduction to FMEA (5 minutes):
• Brief overview of what FMEA is: A structured approach to identifying and evaluating potential failures in a process, system, or product and their effects.
• Explain how FMEA can be applied to Digital Support Services—e.g., improving system reliability, preventing service outages, and enhancing user experience.
2. Group Work: Failure Mode Identification (10 minutes):
Divide students into small groups (3-5 members). Each group will brainstorm potential failure modes in the User Account Management System.
Examples of Failure Modes:
• Incorrect password resets (users unable to reset their passwords due to system errors).
• Delayed account activation (users not receiving timely access to their accounts).
• Misassigned user roles (users receiving incorrect permissions).
• Security vulnerabilities (users gaining unauthorised access).
3. FMEA Analysis (10 minutes):
Each group will use the FMEA method to analyse one or two failure modes identified earlier.
For each failure mode, they must:
• Identify the potential effects (e.g., user frustration, system downtime).
• Rate the severity (how serious the effect is on the system or users) on a scale of 1 to 10.
• Identify the causes (e.g., human error, software bugs, incorrect configurations).
• Rate the occurrence (likelihood of the failure happening) on a scale of 1 to 10.
• Identify current controls (e.g., automated password reset system).
• Rate the detection (how likely the system can detect the failure before it occurs) on a scale of 1 to 10.
• Suggest improvements to reduce the risk of failure (e.g., better user training, enhanced system logging).
4. Presentation and Discussion (5 minutes):
Each group will present one failure mode and their FMEA analysis to the class, focusing on the failure’s severity, likelihood of occurrence, and proposed solutions. The instructor and other groups can ask questions and provide feedback.
Example to Support Understanding:
Failure Mode: Incorrect Password Resets
• Effect: Users are unable to access the system, leading to frustration, productivity loss, and increased support calls.
• Severity: 8 (high, since access is crucial for daily operations).
• Cause: Incorrect configuration of the password reset system or outdated email templates.
• Occurrence: 5 (moderate, occurs occasionally but not frequently).
• Current Controls: Automated password reset tool, email notifications.
• Detection: 6 (moderate, failures are reported by users, but the system does not automatically detect the issue).
• Suggested Improvement: Introduce a monitoring system that alerts support staff when password resets fail and implement regular audits of the reset tool.
Expected Outcome:
Students will gain a practical understanding of FMEA as a tool for improving Digital Support Services by identifying and addressing potential failure points. The exercise will also help them develop teamwork and presentation skills as they discuss their findings and propose solutions.
Materials Required:
• FMEA templates (paper or digital)
• Scenario description (provided in the activity)
• Whiteboard/flip chart for group presentations
Event tree analysis (ETA)
Event Tree Analysis (ETA) is a method used to evaluate how an event or failure could progress and what consequences it might lead to. It starts with a single event, called an “initiating event”, and from there, branches out like a tree, showing different possible outcomes. This analysis is especially useful in safety and risk assessments because it helps identify how different systems, processes, or actions can either stop or allow the event to get worse.
How ETA Works:
1. Identify the initiating event – This could be anything, from a system error to a power outage.
2. Identify the systems or processes designed to respond – For each step, there might be safety systems or processes that can either work (success) or fail (failure).
3. Create branches for each decision point – If something works, the branch leads to a positive outcome. If something fails, the branch leads to a more negative outcome.
4. Evaluate consequences – Each branch ends in a possible outcome, ranging from “nothing happens” to a serious failure.
Example Situations in Digital Support Services:
In digital support services, where businesses provide technical help and maintain digital infrastructure, ETA can help assess risks related to system failures or cyber-attacks.
Example 1: System Outage in a Cloud Service Provider
Imagine a situation where a cloud service provider (like Google Cloud or Amazon Web Services) experiences a major power
Activity:
Event Tree Analysis (ETA) in Digital Support Services Objective:
To research and understand how Event Tree Analysis (ETA) can be applied in digital support services, particularly focusing on system failures, cyber-attacks, or technical errors. Students will present their findings in a 5-minute presentation, showing their understanding of ETA and how it applies to real-world scenarios.
Instructions:
1. Choose a Scenario:
• Select a situation in digital support services where ETA could be applied. Examples include:
• A cyber-attack on a company’s network.
• A system failure or outage in a cloud service provider.
• A technical error in a data centre causing partial downtime.
• Think about what the initiating event might be, and what the potential outcomes could be, based on whether systems work or fail.
2. Research ETA in Digital Systems:
• Spend 10-15 minutes researching the use of Event Tree Analysis in the context of digital systems. Use the following guiding questions:
• What is ETA, and how does it help assess risk?
• How does ETA apply in scenarios like system failures or cyber-attacks?
• What are some real-world examples where ETA has been used in digital services?
3. Sources for Research:
• Health and Safety Executive: Event Tree Analysis – A basic guide to ETA and how it works.
• ScienceDirect: Event Tree Analysis – A detailed overview of ETA and its applications.
• Cloud Computing Incidents Database – Real-world cases of cloud service outages and failures, which can be useful for examples.
• Cyber Security and Infrastructure Agency (CISA) – Information on cyber-attacks and system vulnerabilities.
4. Create a Presentation:
• Spend 15 minutes compiling your findings into a short presentation. Your presentation should include:
• A brief explanation of Event Tree Analysis.
• The scenario you selected (e.g., system failure, cyber-attack) and its potential consequences.
• A simple event tree diagram showing the possible outcomes (you can draw this or create it digitally).
• A conclusion explaining why ETA is useful in digital support services.
5. Presentation Requirements:
• The presentation should last 5 minutes.
• Be ready to explain your event tree and how you arrived at the possible outcomes.
Pareto chart
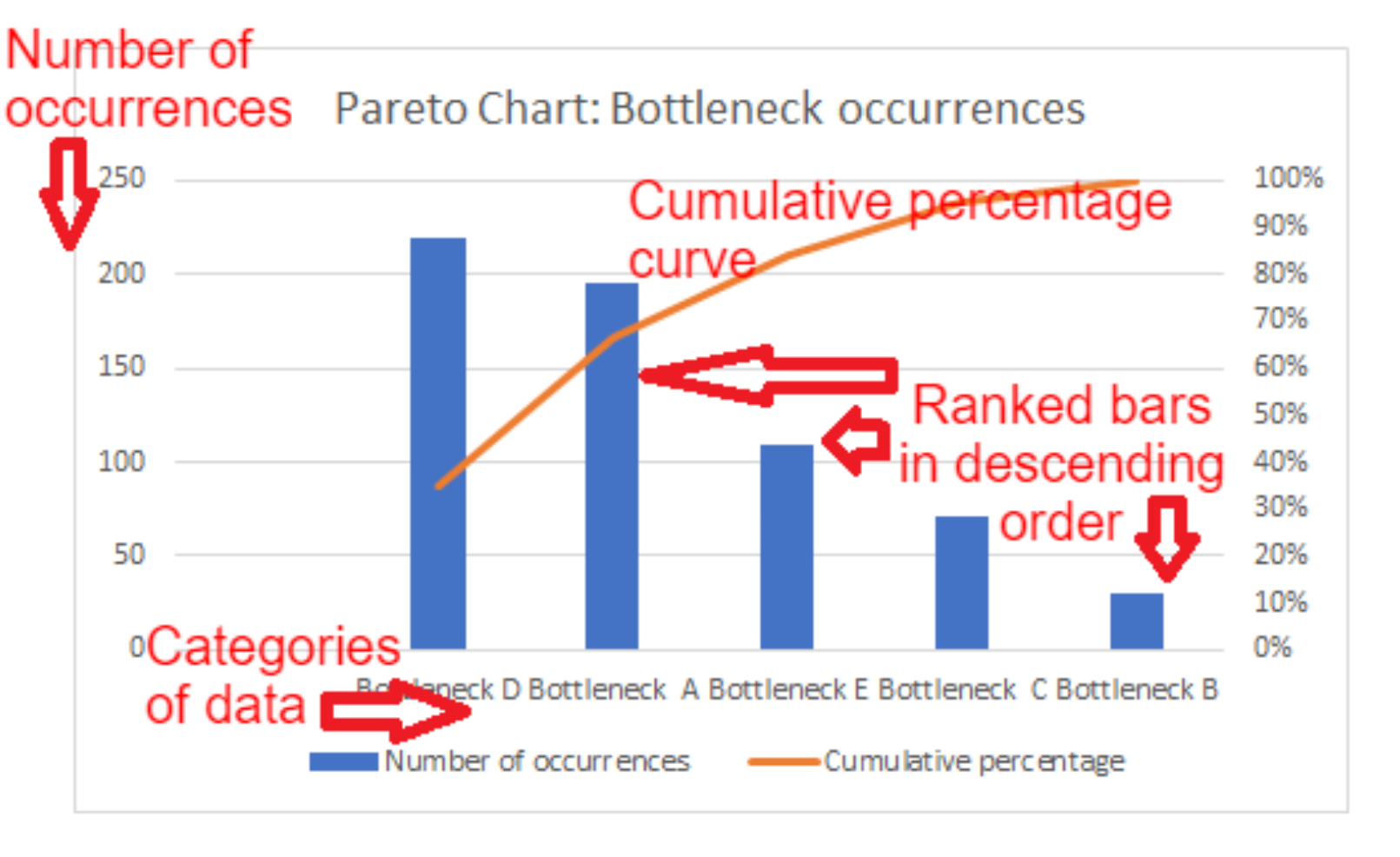
A Pareto chart is a type of bar chart combined with a line graph. It displays the relative frequency or significance of problems or factors in descending order, with the bars representing individual values (e.g., issues or defects) and the line graph showing the cumulative total. The principle behind the chart is based on the Pareto principle (80/20 rule), which suggests that 80% of problems are often caused by 20% of the causes. It helps in identifying the most significant factors that need attention to achieve improvement efficiently.
In the digital support services sector, particularly within IT, Pareto charts are commonly used to identify and prioritise issues in systems, applications, or processes. They help organisations focus on the most impactful problems, improving response times and customer satisfaction by addressing the major pain points.
Example 1: Amazon Web Services (AWS)
AWS uses Pareto charts to identify common causes of service disruptions or support tickets. By analysing data from their support system, AWS can determine which types of incidents are most frequent and impactful. For instance, 80% of all support tickets might be traced back to a handful of misconfigurations or recurring errors in their services. By addressing these high-frequency issues, AWS can improve their platform’s reliability and reduce the volume of incoming support requests.
Why they use it: AWS benefits from Pareto charts as they allow them to pinpoint major operational issues and focus resources on solving the most critical problems, improving the overall user experience and reducing operational costs.
Example 2: Google Cloud
Google Cloud applies Pareto charts in analysing downtime reports and customer feedback related to their cloud infrastructure services. A Pareto analysis helps them quickly see which factors (e.g., network outages, storage failures) are causing the most significant disruptions. By concentrating their efforts on resolving the top 20% of root causes, Google Cloud can greatly reduce system downtime and improve the resilience of their services.
Why they use it: By using Pareto charts, Google Cloud can effectively prioritise their engineering efforts on the key issues affecting customer experience, helping them optimise service performance and reduce maintenance costs.
Activity: Identifying and Solving Common IT Issues Using a Pareto Chart
Objective:
Students will work in small groups to identify common IT support issues within a fictional company and use a Pareto chart to prioritise them. They will learn how to apply the Pareto principle (80/20 rule) in problem-solving and improve their understanding of how this can be used in real-life digital support services.
Materials Needed:
• Flipchart paper or whiteboard
• Markers
• Printed handouts with a list of common IT issues (or displayed on screen)
• A blank Pareto chart template (can be on paper or digitally)
Time: 25 minutes
Instructions:
Step 1: Introduction to the Problem (5 minutes)
• Briefly explain the Pareto principle and how a Pareto chart works.
• Introduce the scenario: The group is working as part of the IT support team for a small company. Over the past month, several technical issues have been recorded by the support team.
• Show them a list of the common IT issues the company is facing (example list below):
• Network outages
• Software crashes
• Email access problems
• Slow internet speed
• Printer malfunctions
• Password reset requests
• Hardware malfunctions
Step 2: Group Discussion (5 minutes)
• In groups of 2-3, students should discuss the list of IT issues. They should use their knowledge to think about which of these problems might occur most frequently and which are likely to have the biggest impact on the company’s operations.
Step 3: Prioritisation and Creation of a Pareto Chart (10 minutes)
• Each group should select the top 5 issues they believe would cause 80% of the problems in the company.
• Using the blank Pareto chart template, they should rank the issues from most frequent to least frequent, drawing bars to represent each issue’s frequency.
• They should also create the cumulative line to show how solving the top issues will address the majority of the problems.
Step 4: Group Presentation (5 minutes)
• Each group will briefly present their chart and explain their reasoning behind the prioritisation of issues. They should discuss how focusing on the top problems can help reduce overall downtime and improve service for the company.
Example for Student Understanding:
Scenario:
In your fictional company, after analysing the data, you find that password reset requests are the most frequent issue, followed by slow internet speed, network outages, printer malfunctions, and email access problems.
Using the Pareto chart, the group can show that password reset requests and slow internet speed make up the bulk of the problems (say, 60%). By addressing these two key issues, they can reduce the number of support tickets significantly and improve the company’s efficiency.
Outcome:
By the end of the activity, students will have a clear understanding of how to prioritise issues using the Pareto chart, and they will understand its practical application in IT support services.
Scatter diagram
A scatter diagram (also known as a scatter plot) is a type of graph that helps to identify if there is a relationship between two different factors, also called variables. It plots individual data points on a graph, with one variable along the x-axis (horizontal) and the other along the y-axis (vertical). Each dot on the graph represents one instance or observation of the data, showing where the two variables intersect.
How Scatter Diagrams Help Identify Relationships
In digital support services, scatter diagrams are useful for identifying patterns between different aspects of service quality, customer satisfaction, or system performance. By plotting the data, you can visually see whether there’s a relationship, or correlation, between the two variables.
There are three main types of relationships you might observe:
1. Positive correlation: As one variable increases, the other also increases (e.g. the more time a customer spends on a website, the more they are likely to purchase).
2. Negative correlation: As one variable increases, the other decreases (e.g. as response time for customer queries decreases, customer satisfaction increases).
3. No correlation: The two variables don’t seem to affect each other at all (e.g. response time might have no clear effect on sales in some cases).
Example in Digital Support Services
Consider a digital support services company that wants to understand how response time affects customer satisfaction. They could gather data from customer service logs (response time) and customer feedback scores (satisfaction ratings). By plotting response time on the x-axis and satisfaction scores on the y-axis, they could create a scatter diagram to see if there’s any visible relationship. If the points trend upwards, it would suggest a positive relationship—quicker response times lead to higher satisfaction.
Case Study Examples
1. Amazon
As a company focused on customer satisfaction, Amazon could use scatter diagrams to assess how the speed of responses from customer service representatives affects overall customer satisfaction scores. By plotting the response time (x-axis) and customer ratings from surveys (y-axis), they could easily see whether faster responses lead to better reviews, helping them to improve their services.
2. Zendesk
Zendesk, a customer service software company, might use scatter diagrams to assess system performance metrics. For example, they could examine whether the number of support tickets open (x-axis) impacts average resolution time (y-axis). If they spot a positive correlation, it could signal that too many open tickets slow down resolution times, which would require action to streamline processes.
3. Netflix
Netflix may use scatter diagrams to track how app performance (like load times) influences user engagement. For instance, by plotting app load time (x-axis) against viewing hours (y-axis), they might see whether faster load times lead to more content being watched, which would help them optimise their app to reduce buffering times and boost user satisfaction.
Investigating the Relationship Between Response Time and Customer Satisfaction
Objective:
You will use a scatter diagram to explore the relationship between customer support response time and customer satisfaction ratings, simulating a real-world scenario in the digital support services sector.
Time: 30 minutes
Instructions:
Scenario:
You are working for a digital support services company that wants to assess how quickly customers receive responses to their queries and how that affects their satisfaction. Your task is to create a scatter diagram to visually explore if there’s any correlation between response time (in hours) and customer satisfaction (rating out of 10).
Step-by-Step Guide:
1. Data Collection (10 minutes)
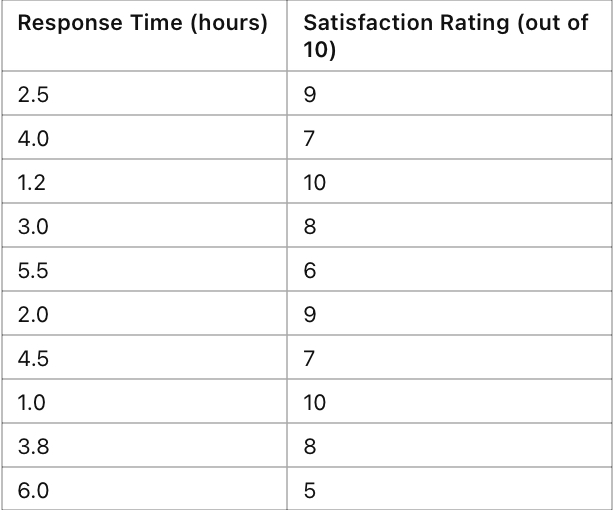
Below is a set of fictional data showing response times (in hours) and customer satisfaction ratings (out of 10). Use this data to complete the activity:
2. Plotting the Data (10 minutes)
Using either graphing software (Excel, Google Sheets) or graph paper:
• Plot Response Time on the x-axis (horizontal).
• Plot Satisfaction Rating on the y-axis (vertical).
• Mark each data point with a dot on the graph where the x and y values intersect.
3. Analysis (10 minutes)
Answer the following questions based on your scatter diagram:
• Is there a clear pattern? Do you see a positive or negative trend, or is there no clear relationship between response time and customer satisfaction?
• Describe the trend (if any). Does customer satisfaction decrease as response time increases?
• Identify any outliers (points that don’t fit the pattern). What might be the reason for these outliers in real-world scenarios (e.g., a particularly complicated customer issue)?
4. Generate Evidence:
• Take a screenshot or photo of your scatter diagram (if using software or graph paper).
• Write a short paragraph (3-5 sentences) describing the relationship between the two variables (response time and satisfaction), supported by what you observed from your diagram.
Deliverables:
• A scatter diagram (either digital or hand-drawn).
• A paragraph describing the relationship between response time and customer satisfaction, based on your graph.
Extension (optional, if time allows)
If you finish early, consider what actions a company might take based on the results. How could they reduce response times to improve customer satisfaction?
Materials Needed:
• Laptop or tablet with access to Excel/Google Sheets (or graph paper and a pencil)
• Data provided above for plotting
Files that support this week
English:
Assessment:
Learning Outcomes:
Awarding Organisation Criteria:
Maths:
Stretch and Challenge:
E&D / BV
Homework / Extension:
ILT
→
→
→
→
→
→
Week 4
T&L Activities:
Learning Aims and Objectives:
Aim: In this week's page, students will learn the
Objectives:
1. By the end of this week's page students will be able to.
2. By the end of the week's page students will be able to.
P3.4 The principles of incident management (for example Information Technology Infrastructure Library (ITIL®)) models in the context of digital support services
Incident management is a process used to deal with problems (referred to as “incidents”) that occur when using technology or digital services, such as computers, websites, or apps. For instance, if a website crashes or a computer system stops working, that’s an incident.
One of the most widely used frameworks for managing incidents is called ITIL® (Information Technology Infrastructure Library). ITIL provides a structured set of steps to ensure incidents are fixed quickly and don’t cause bigger issues.
ITIL was created by the UK Government’s Central Computer and Telecommunications Agency (CCTA) in the 1980s. It started as a way to standardise IT practices across different government departments. As ITIL became more popular in the private sector, it was published as a series of books, which came to be known as the ITIL library.
In 2013, AXELOS Limited was set up as a partnership between the UK Government’s Cabinet Office and Capita plc. AXELOS took over the management and ownership of ITIL, along with other well-known frameworks like PRINCE2 and MSP. Under AXELOS, ITIL has continued to develop, keeping up with new technology and business practices.
How Incident Management Works
1. Identify the incident: This is when someone notices there’s a problem. It could be a user calling support to say they can’t log into a website, or an alert showing a server is down.
2. Log the incident: The details of the problem are recorded in a system so it can be tracked. This helps to organise the work and ensure nothing gets forgotten.
3. Classify the incident: Not all incidents are equal. For example, if one person can’t access a service, it’s important but not as urgent as if the whole service is down for everyone. The incident is ranked by how serious it is (high or low priority).
4. Assign the incident: The problem is sent to the correct team or person who can fix it. For example, if it’s a network issue, it will go to the network team.
5. Resolve the incident: The team works to fix the issue as quickly as possible. Once it’s fixed, they ensure everything is working normally again.
6. Close the incident: After confirming that the problem is solved, the incident is closed in the system.
Example of Incident Management in Use
• E-commerce websites: If a site like Argos’ checkout system stops working, that’s a significant incident. The incident management team would receive an alert, determine the cause (perhaps a server issue), and work swiftly to resolve it to avoid losing customers or revenue.
• Schools and Universities: If an online learning platform crashes during an important exam, the IT team would treat this as a high-priority incident and work to restore it as quickly as possible.
Benefits of Using Incident Management (ITIL)
1. Efficiency: Having a structured approach means incidents are resolved faster, reducing downtime and ensuring services are restored quickly.
2. Organisation: With each incident being tracked and assigned properly, teams can avoid confusion and ensure the right person is working on the problem.
3. Prevents Recurrence: After resolving an incident, the team can review what went wrong to prevent it from happening again, leading to better service overall.
4. Improves Customer Satisfaction: The quicker and more efficiently issues are resolved, the more satisfied customers or users are with the service.
Disadvantages of Using Incident Management (ITIL)
1. Time-Consuming: Following a structured process takes time. In less critical situations, it might feel like more effort than it’s worth.
2. Requires Training: Those handling incidents need to be familiar with the ITIL process, and training can take time and resources.
3. Rigid Structure: In some cases, the strict rules of ITIL may slow things down. If something is urgent but not classified as high priority under the system, the process might delay a quick fix.
4. Overhead: Small organisations with fewer incidents may find the ITIL-based system too formal or costly to maintain, as it’s designed for larger operations.
Detection
Detection in Incident Management: Reporting and Recording
The detection stage of incident management is critical, as it’s the first step in identifying and responding to problems that occur within digital support services. This phase focuses on the reporting and recording of incidents, ensuring they are captured and tracked accurately.
Reporting the Incident
Incidents can be detected in different ways, and the reporting process involves bringing attention to a problem. There are two main types of reporting:
1. User-reported incidents: These are issues that are brought to the attention of the IT or support team by the users themselves. For example, a student might report that they are unable to access their online learning portal, or a customer may contact a help desk because a website is not loading properly. Users play an important role in helping identify problems early, especially when automatic systems don’t detect them.
2. System-reported incidents: Many digital services use monitoring tools that automatically detect when something goes wrong. These systems can track things like server performance, website traffic, or errors within an application. If something unusual happens, such as a spike in errors or a system crashing, the monitoring system will generate an alert that reports the incident to the IT team without any human intervention.
Recording the Incident
Once an incident is reported, the next step is to record it in a central system, such as an incident management tool. This is important for several reasons:
1. Tracking and organisation: Recording incidents ensures that each one is properly tracked and monitored. By logging details like the time, type of issue, and who reported it, the team can stay organised and make sure nothing is missed. It also allows the team to see patterns over time, which can help in identifying recurring problems. 2. Prioritisation: When incidents are recorded, they can be classified based on their severity or impact. This allows the IT team to prioritise their work. For example, an issue affecting a large number of users would be recorded as high priority, while a minor issue affecting a single user might be recorded as low priority. 3. Audit trail: Recording incidents creates a clear history of what issues have occurred and how they were handled. This is important for accountability and reviewing how effectively incidents are being managed. It also helps in future problem-solving, as the team can look back at how similar incidents were resolved in the past. 4. Improving future responses: The data collected during the recording process can be used to improve incident management over time. By analysing the types of incidents that occur and how they are resolved, teams can adjust their processes to be more efficient and effective in the future.
Response
Response in Incident Management: Ownership, Resolution, and Recording
Once an incident is detected and recorded, the next crucial phase is the response. This involves identifying who is responsible for handling the issue, working to resolve the problem and restore normal service, and documenting how the incident was resolved.
Identifying an Owner
After an incident is recorded, it must be assigned to the correct person or team, known as the owner of the incident. The owner has responsibility for managing the issue until it is fully resolved. Identifying the right owner is essential for efficient incident management, and this process often depends on the type of incident:
1. Assigning based on expertise: Different teams or individuals may specialise in certain areas, such as network issues, server maintenance, or application development. For example, if the issue involves a server being down, the incident would likely be assigned to the infrastructure team. If it’s a software bug, it might go to the development team.
2. Clear responsibility: By having a designated owner, it is clear who is accountable for managing the incident. This avoids confusion, ensures that the incident is being actively worked on, and prevents duplication of effort.
3. Escalation procedures: If the incident is complex or severe, it may need to be escalated to a higher-level team or manager. This is particularly important for high-priority incidents that impact large numbers of users or critical services.
Resolving the Issue and Restoring Service
Once an owner is identified, the next step is to focus on resolving the incident and restoring normal service. This involves diagnosing the root cause of the problem and implementing a solution to fix it.
1. Diagnosis and troubleshooting: The incident owner will start by identifying the cause of the issue, which may involve investigating system logs, reviewing recent changes, or running diagnostic tests. For example, if a website is down, the owner might check whether there’s an issue with the server or if a recent software update caused the problem.
2. Implementing a fix: Once the cause is identified, the owner works on resolving the issue. This might involve repairing hardware, restoring backups, patching software, or rolling back a faulty update. The key goal is to restore the service as quickly and effectively as possible.
3. Minimising impact: Throughout the resolution process, the owner will aim to minimise the impact on users. This could involve providing regular updates to affected users or setting up temporary workarounds to ensure some level of service is maintained while the main issue is being fixed.
Recording Incident Resolution and Applied Changes
Once the incident is resolved, it’s important to record the resolution and any changes that were applied to fix the issue. This final step ensures that the incident is fully documented and can be reviewed later if necessary.
1. Documenting the solution: The details of how the incident was resolved are recorded in the incident management system. This includes what caused the problem, the steps taken to fix it, and whether any changes were made to prevent it from happening again.
2. Review and learning: Recording the resolution helps build a knowledge base that can be referred to in the future. If a similar incident occurs, the team can look back at how it was previously handled, which can speed up future responses and improve overall service management.
3. Preventing recurrence: By reviewing recorded incidents, teams can spot trends or recurring problems. This allows them to implement proactive measures to prevent future incidents, such as updating software more carefully or improving system monitoring.
4. Closure and feedback: Once the incident is resolved and recorded, the incident is formally closed. Feedback can also be gathered from users or stakeholders to evaluate how effectively the incident was handled, which helps improve future responses.
Intelligence
The intelligence aspect of incident management focuses on what can be learned from each incident to prevent future occurrences and improve overall service quality. It involves carefully recording lessons learned, investigating the root cause, and using that knowledge to update procedures and reduce the risk of similar incidents happening again.
Recording Lessons Learned, Fixes, and Procedure Updates
After an incident is resolved, it is vital to record all lessons learned during the process. This step ensures that the organisation can learn from the experience and improve its incident management approach.
1. Documenting the lessons: Once an incident has been resolved, the team reflects on what went well, what challenges were faced, and how things could be done better next time. These insights are recorded in detail so they can be reviewed in future incidents.
2. Recording fixes: Any specific fixes or technical changes applied to resolve the issue are documented. For example, if a software bug was fixed, the team would note exactly what was done, such as applying a patch or updating a configuration. This provides a reference for dealing with similar issues in the future.
3. Updating procedures: If the incident revealed flaws or gaps in the current processes, these procedures should be updated. For example, if it took too long to detect the incident, the monitoring systems might need to be improved. Procedure updates ensure that the organisation is better prepared next time.
Performing In-Depth Investigation and Root Cause Analysis
Once an incident is resolved, it’s essential to investigate thoroughly to understand the underlying cause, especially if the issue was complex or had a significant impact. This can prevent the same problem from recurring in the future.
1. Root cause analysis: An in-depth investigation is performed to identify the true cause of the incident, rather than just addressing the symptoms. For example, if a website crashed, was it due to a server overload, a software bug, or a misconfiguration? Understanding the root cause ensures that the real problem is fixed, not just the immediate issue.
2. Forensic analysis: In more complex or security-related incidents, such as a data breach or system failure, a forensic analysis may be required. This involves a detailed examination of system logs, network activity, and other data to uncover exactly what went wrong and how the incident occurred. Forensic analysis can provide valuable insights into vulnerabilities or weaknesses in the system.
3. Identifying patterns: By performing detailed analysis on multiple incidents over time, patterns may emerge that highlight broader issues. For example, if similar incidents keep occurring, it could point to an underlying flaw in the system architecture that needs addressing.
Sharing Lessons Learned for Continual Improvement
A key part of the intelligence aspect of incident management is sharing lessons learned to improve the organisation’s overall capability and reduce the likelihood of incidents repeating.
1. Internal knowledge sharing: Once lessons have been documented, they should be shared across teams to ensure everyone is aware of the insights gained. This could involve team meetings, reports, or internal documentation. For example, if a particular fix worked well, other teams should know about it so they can apply it in similar situations.
2. Contributing to continual improvement: The insights gained from each incident are fed into the continual improvement process. This means that incident management procedures, response times, and technical systems are constantly evolving to become more effective over time. Continual improvement also helps the organisation stay agile in responding to new and emerging types of incidents.
3. Reducing the risk of repetition: The ultimate goal of recording and sharing lessons is to reduce the risk of similar incidents happening again. By identifying the root causes and updating procedures, the organisation can minimise vulnerabilities and ensure future incidents are less likely to occur.
4. Developing preventative measures: Armed with lessons from past incidents, the organisation can proactively implement preventative measures. For example, if a particular type of cyberattack caused an incident, stronger security measures can be put in place to prevent similar attacks in the future.
Activity: Incident Management Group Task
You have been asked to work in teams of up to three students to create a presentation on incident management based on the principles we’ve discussed: detection, response, and intelligence. The aim is to demonstrate your understanding of how incidents are reported, managed, resolved, and learned from, using a real-world scenario.
You will have 30 minutes to complete this activity. Your group will need to explain the following in your presentation:
1. Detection: How was the incident identified and reported?
• Was it a user-reported issue or system-reported?
• How was it logged, and what details were recorded?
2. Response: Who was responsible for fixing the issue, and how was it resolved?
• How was the incident assigned, and what steps were taken to resolve it?
• What actions were necessary to restore normal service?
3. Intelligence: What lessons were learned from the incident?
• Was an in-depth investigation done to find the root cause?
• How could the organisation use this experience to prevent similar incidents in the future?
Scenario Example: Online Learning Platform Crash
Imagine you are part of the IT support team at a college, and one day during an important mock exam, the college’s online learning platform crashes. Students cannot access their exam papers, and teachers are panicking. Your job is to manage the incident from start to finish.
• Detection: The incident is first reported by a teacher who notices students can’t log in. Shortly after, a system alert shows that the platform’s server is down.
• Response: The IT support team assigns the incident to the infrastructure team, who investigates and finds that a recent update overloaded the server. They restore the platform by rolling back the update, and the students can continue their exams.
• Intelligence: After the incident, the team conducts an analysis and realises that the system wasn’t tested properly after the update. The team decides to implement a new procedure for testing updates before they are applied.
Your group will use this scenario, or create your own similar one, to guide your presentation. Make sure to:
• Explain the detection process (how was the problem reported and logged?).
• Describe the response (who was responsible, and what steps were taken to fix it?).
• Discuss the intelligence gathered (what lessons were learned, and how can future issues be prevented?).
You will have 5 minutes at the end of the 30 minutes to present your findings. Good luck!
Files that support this week
English:
Assessment:
Learning Outcomes:
Awarding Organisation Criteria:
Maths:
Stretch and Challenge:
E&D / BV
Homework / Extension:
ILT
→
→
→
→
→
→
Week 5
T&L Activities:
Learning Aims and Objectives:
Aim: In this week's page, students will learn the
Objectives:
1. By the end of this week's page students will be able to.
2. By the end of the week's page students will be able to.
P3.5 The requirements for external reporting of faults and problem resolution:
To comply with relevant legislation, regulations and external standards (for example report to the Information Commissioner’s Office (ICO))
What is the ICO and what is thier remit?
Freedom of information act
Data Protection Act
Using the following link reflect and review the case studies that the ICO have provided. ICO Case Studies