week 6
3.6 Structures for storing data3.6.1 Understand the role of metadata in providing descriptions and contexts for data.
When data is created, stored, or transmitted, it often needs additional information to make it meaningful and useful. This is where metadata comes in. Metadata is often described as “data about data.” It provides descriptions, context, and structure that help people and systems understand, manage, and organise the main data.
Without metadata, a file, dataset, or digital object would just be raw content with no clear meaning. For example, a photo file would only contain pixel data, but metadata can add context such as when it was taken, who took it, the camera settings, and even GPS location. This descriptive information makes data easier to search, retrieve, interpret, and manage.
Definition and Purpose of Metadata
-
Definition: Metadata is information that describes the characteristics, properties, or context of data. It does not alter the data itself but provides supporting details that enhance understanding and usability.
-
Purpose:
-
To give context (e.g., who created the data, when, and why).
-
To aid organisation and retrieval (e.g., library catalogues, search engines).
-
To support data governance and security (e.g., permissions, classification).
-
To provide interoperability across systems (e.g., file sharing between applications).
-
Roles, Uses, and Examples of Metadata
1. Descriptive Metadata
-
Role: Provides information about the content.
-
Use: Used in catalogues, search engines, and digital libraries to help users find resources.
-
Example: A library entry describing a book’s title, author, and ISBN.
-
Compatible Software: Library management systems, online catalogues, search engines.
2. Structural Metadata
-
Role: Describes how data is organised and related.
-
Use: Ensures systems know how to present and link parts of data together.
-
Example: A website sitemap XML file showing the hierarchy of web pages.
-
Compatible Software: Web browsers, content management systems (WordPress, Drupal).
3. Administrative Metadata
-
Role: Provides information on how to manage the data.
-
Use: Supports digital rights management, storage, and file control.
-
Example: A PDF document with embedded copyright information and file type details.
-
Compatible Software: Adobe Acrobat, Windows Explorer (file properties), cloud storage (Google Drive, OneDrive).
4. Technical Metadata
-
Role: Describes technical details of a file or dataset.
-
Use: Enables correct use and interpretation of digital objects.
-
Example: Photo metadata storing resolution, bit depth, and colour model.
-
Compatible Software: Photoshop (EXIF data), Lightroom, data warehouses.
5. Provenance Metadata
-
Role: Records the history and origin of the data.
-
Use: Ensures trust and authenticity of data.
-
Example: Audit trails in a database showing who edited a record and when.
-
Compatible Software: SQL databases, SharePoint, Git version control.
Real-World Examples of Metadata
A Word document contains metadata such as author, word count, and last modified date.
A music file (MP3) includes metadata tags for artist, album, and genre.
A digital photograph stores EXIF metadata for camera model, GPS coordinates, and shutter speed.
A dataset in a data warehouse uses metadata to describe field names, data types, and relationships.
“Making Data Meaningful – The Power of Metadata”
Time: 30–40 minutes (including prep + presentation)
Instructions for Students
Part 1 – Explore Metadata (10 mins)
In small groups (2–3 students), open different types of files on your computer (e.g., Word document, PDF, photo, or MP3 file).
Right-click the file and check Properties (Windows) or Get Info (Mac).
Record the metadata you can find, such as:
- Author/creator
- Date created/modified
- File size
- Keywords/tags
- Technical details (resolution, encoding, etc.)
Part 2 – Research Case Studies (10–15 mins)
Research one real-world case study where metadata is essential. Examples could include:
- Photography – how EXIF metadata (camera settings, GPS location) is used in photo management or digital forensics.
- Music/Film – how metadata in MP3s/MP4s allows Spotify or Netflix to categorise and recommend content.
- Cybersecurity – how hidden metadata in documents (e.g., author names in leaked Word/PDF files) has exposed sensitive information.
- Libraries & Archives – how descriptive metadata helps catalogues and digital archives stay searchable.
Prepare 2–3 key points from your chosen case study to share.
Part 3 – Present Your Findings (10–15 mins)
Each group should prepare a short presentation (3–4 minutes) covering:
- Definition: What metadata is in your own words.
- Examples: Metadata you found in your own files.
- Case Study: The real-world use of metadata you researched.
- Impact: Why metadata is valuable in making data more useful and reliable.
Stretch / Challenge Task
Discuss as a group: Can metadata ever be a risk? (e.g., GPS location data in photos uploaded online, exposing personal info).
Suggest one security measure organisations can use to manage metadata safely.
3.6.2 Know the definition of file-based and directory-based structures and understand their purposes and when they are used.
All digital systems must store and organise data in ways that make it easy to access, manage, and retrieve. Two of the most common organisational models are file-based structures and directory-based structures.
-
A file-based structure focuses on storing data in individual, stand-alone files. Each file is independent and may not directly connect with other files, meaning data can be duplicated or difficult to share between systems.
-
A directory-based structure is more organised, using folders (directories) and subfolders (subdirectories) to group related files. This hierarchy makes it easier to navigate and manage large sets of data.
Both approaches are still used today, and the choice depends on data complexity, collaboration needs, and the scale of storage required.
File-Based Structures
Definition
A storage model where data is stored in independent files, often with no enforced relationships between them. Each file is self-contained.
Purpose & Use
-
Simple and low-cost way to store and access data.
-
Common for personal use, small systems, or applications where data doesn’t need to be shared widely.
-
Used when performance and simplicity are more important than complex data relationships.
Examples & Case Studies
-
Case Study 1 – Small Business Accounting:
A local shop saves all its sales records in Excel spreadsheets and stores them as individual files (e.g.,Jan_sales.xlsx,Feb_sales.xlsx). This is easy to set up but leads to duplication of customer details and makes cross-checking totals more time-consuming. -
Case Study 2 – Medical Practice (Legacy Systems):
An older clinic database saves each patient’s record in a separate file. This makes searching slow and creates issues when patients have multiple files across departments.
Software Examples
-
Microsoft Excel / Access (file-based storage)
-
CSV or text files in data logging systems
-
Legacy business systems
Directory-Based Structures
Definition
A hierarchical storage model where files are grouped into directories (folders) and subdirectories, providing a structured way to organise information.
Purpose & Use
-
Provides a clear hierarchy and reduces duplication.
-
Easier navigation and searching across large datasets.
-
Common in operating systems, enterprise systems, and cloud storage where data is shared and must be controlled.
Examples & Case Studies
-
Case Study 1 – Corporate File Server:
An IT company uses a shared drive with directories likeProjects > 2025 > ClientX > Reports. This makes it simple for teams to collaborate while keeping data well organised. Metadata (permissions, timestamps) helps manage access. -
Case Study 2 – University Learning Platform:
A university stores student submissions in directories by course and module (Course > Module > StudentID). This ensures work is easy to locate and secure. -
Case Study 3 – Cloud Collaboration (Google Drive/SharePoint):
Teams working remotely store documents in shared directories, ensuring all members see the same updated files without creating multiple versions.
You are going to investigate the difference between file-based and directory-based structures, using the case studies provided. Your task is to show your understanding by applying real-world reasoning and producing a short written or visual response.
Instructions
Part 1 – Compare the Structures (10 mins)
1. Write down two key features of file-based structures.
2. Write down two key features of directory-based structures.
3. Explain in your own words why a small business (e.g., local shop with sales spreadsheets) might choose a file-based structure instead of a directory-based one.
4. Explain why a university or IT company would prefer directory-based storage instead of file-based.
Part 2 – Case Study Scenarios (10 mins)
For each scenario below, decide whether a file-based structure or a directory-based structure would be best. Write 2–3 sentences explaining your choice.
Scenario A: A freelance photographer saves all their client photos. Each photoshoot needs to be kept separate but easy to find later.
Scenario B: A multinational corporation needs to share HR records across several countries, with access restrictions for different teams.
Scenario C: A student keeps lecture notes on their personal laptop. Each week’s notes are saved in Word files.
Part 3 – Reflection (5 mins)
In one short paragraph, explain which structure you personally use most often (on your own computer, cloud storage, or phone).
Why does that structure suit your needs?
Output Options
You can present you work as:
A written response (1–2 pages).
A diagram or mind map comparing file vs directory structures with examples.
3.6.3 Know the definition of hierarchy-based structure and understand its purpose and when it is used.
A hierarchy-based structure is a method of organising data in a parent–child arrangement, where each item (or “child”) is linked to a single higher-level item (its “parent”). This creates a tree-like structure, starting from a top node and branching downward into sub-levels.
For example, in a computer file system:
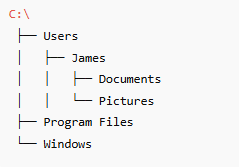 Each folder (child) belongs to one parent, allowing clear paths and logical navigation.
Each folder (child) belongs to one parent, allowing clear paths and logical navigation.
The main purpose of a hierarchy-based structure is to store and organise data efficiently so that relationships between items are clear and retrieval is straightforward. It:
-
Simplifies data navigation by using parent–child relationships.
-
Provides logical grouping of related items.
-
Supports data inheritance, where lower levels can inherit attributes from higher ones (e.g. file permissions).
-
Enhances clarity and access control, particularly in operating systems, databases, and organisational structures.
Hierarchy-based structures are commonly used when:
-
Data has a natural one-to-many relationship (e.g. folders and subfolders, organisation charts, XML data).
-
Systems require structured navigation or categorisation, such as:
-
File systems (Windows, macOS, Linux)
-
Hierarchical databases (e.g. IBM IMS)
-
XML and JSON data representations
-
Organisational charts (CEO → Managers → Staff)
-
Website navigation menus
-
They are not ideal when data has many-to-many relationships, where relational databases are more suitable.
Understanding Hierarchy-Based Structures
Time: 15 minutes
Type: Individual written and visual task
Resources needed: Paper or digital document, internet access (optional), pen or drawing tool
Task Instructions
Step 1 – Define (3 minutes)
Write a short definition in your own words explaining what a hierarchy-based structure is.
Include:
The meaning of parent and child relationships.
Why data or information might be organised this way.
(Tip: Think of folders on a computer or how staff roles are arranged in a company.)
Step 2 – Create Your Own Hierarchy (7 minutes)
Choose one of the following real-world examples and draw or outline its hierarchy:
Your college folder system (e.g. Courses → Units → Assignments → Files)
An organisation structure (e.g. Principal → Department Head → Teachers → Students)
A website menu layout (e.g. Home → Courses → IT → T-Level Digital Support Services)
Create a tree diagram showing parent and child nodes.
Label each level clearly, showing how information flows from the top (root) down to the lowest level.
Step 3 – Reflect (5 minutes)
Answer these short reflection questions in complete sentences:
Why is a hierarchy-based structure useful for your chosen example?
What problems might occur if this structure was not used?
Can you think of a situation where a hierarchy structure would not work well? Explain why.
What You Should Submit
By the end of this activity, you should have:
- A short written definition (Step 1)
- A hand-drawn or digital hierarchy diagram (Step 2)
- Three short reflection answers (Step 3)
3.6.4 Understand the interrelationships between storage structures and data transformation.
A “storage structure” describes the way in which data is organised, stored and accessed within a system. It covers how pieces of data relate to each other, how they are grouped, how they are indexed, and how the system retrieves or updates them.
For example, data may be stored in a hierarchical structure (a parent → child tree-like model), in relational tables (rows and columns with keys linking them), in flat file lists, or as graph/network models with many-to-many links.
Each type of structure has its own purpose:
-
A hierarchical structure allows quick traversal from a “root” node down through levels of children.
-
A relational structure allows flexible linking of any number of records via keys.
-
A graph/network structure supports complex interconnections such as many-to-many relationships, loops, or relationships between relationships.
How the data is stored influences many things: how fast it can be retrieved, how easy it is to update, how well it supports analytics, and how maintainable it is.
“Data transformation” is the process of taking data in one format, structure or system and converting it into another format or structure that is required for a different purpose. This process often involves cleaning, normalising, aggregating, changing formats/types, removing duplicates, and mapping fields from one structure to another. TIBCO+2Qlik+2
Here’s what typically happens in a transformation process:
-
Discovery/mapping – you identify what data you have and how it is organised. RudderStack+1
-
Transformation operations – you might rename fields, filter rows, aggregate values, join different sources, change data types, restructure the organisation etc. Matillion+1
-
Loading/storing – you place the transformed data into the destination storage structure so it can be used for its intended purpose (e.g., reporting, analytics, operational system). Qlik
Data transformation is essential because raw data comes from many sources (spreadsheets, logs, databases, XML/JSON files, sensor data) in different formats. Unless it is transformed into a compatible form, it may not be usable.
How Storage Structures and Data Transformation Interrelate
The key point is: the choice of storage structure and the process of data transformation are deeply connected. They influence each other.
Structure informs transformation
-
If data is stored in a hierarchical model (e.g., a folder tree or XML with nested elements), then any transformation must take into account those parent–child relationships. For example, you may need to “flatten” nested structures into tables, or map them into relational records.
-
If the storage structure is relational tables, then transformation may involve taking data from flat files or other sources and fitting them into tables with rows, columns and keys.
-
If data will ultimately be analysed using a particular model (say a data-warehouse star schema), then transformation must output data fitting that structure. The target structure dictates the transformation.
Transformation influences structure
-
Sometimes organisations decide to change the storage structure (e.g., moving from a hierarchical system into relational tables). That requires data transformation to convert existing data into the new structure.
-
The nature of transformation (for example, many-to-many joins, creating aggregated summary tables) might lead to an adapted storage structure better suited for that transformed data (e.g., summary tables, data marts).
-
Performance and accessibility considerations of the storage structure (how fast queries can run, how easily data can be retrieved) may shape how transformation is done (pre-aggregate data vs transform on the fly).
The alignment of both ensures usability
If the storage structure and the transformation process are aligned, data becomes accessible, reliable and meaningful. If they are not aligned, you can run into problems: data might be stored in a structure that makes it hard to transform, or transformations produce data that does not fit the storage model, leading to inefficiencies, errors or unusable data.
For instance:
-
A business collects customer data in many formats (CSV, JSON, spreadsheets), and wants to load it into a central relational database for analysis. The transformation must convert formats, standardise fields, resolve duplicates, map into relational tables. If the relational structure was not designed to take the data (e.g., missing keys, mismatched fields), there will be trouble.
-
Similarly, a data warehouse may require data in a specific star-schema structure (fact tables, dimension tables); transformation must build the data into those structures.
Thus, when you design systems or tasks involving data, you need to consider both: what storage structure you’ll use and how you’ll transform data to meet that structure — and they must work together.
Why This Matters in Digital Support Services
For students studying the core of Digital Support Services (and especially the “Security” route element you are creating resources for), understanding this interrelationship is crucial. Because:
-
Data often comes from disparate sources (different departments, formats, legacy systems). Transforming that data so it can be securely stored and accessed is a key activity.
-
The storage structure chosen has implications for security (access controls, encryption, retention), for data consistency and for integrity.
-
Poor alignment between storage structure & transformation can lead to security risks (inconsistent data, non-standard formats, duplication), inefficiencies (longer processing), or data unusability (incorrect reports).
-
In designing solutions (for example: a logging system, incident response database, reports for security controls), students must understand how to structure data appropriately and how to transform incoming data into that structure.
Last Updated
2025-11-13 08:30:15
English and Maths
English
Maths
Stretch and Challenge
Stretch and Challenge
- Fast to implement
- Accessible by default
- No dependencies
Homework
Homework
Equality and Diversity Calendar
How to's
How 2's Coverage
Links to Learning Outcomes |
Links to Assessment criteria |
|
|---|---|---|
Files that support this week
Week 5→
Next 5Week 6→
Next 6Week 7→
Next 7←
Prev5